
A Response to “Becoming Digital”
Digitization: The Basic Methods and Formats
When it comes to taking the analog world and turning it digital, there are a multitude of factors that influence what materials and methods are used. Just as there are different formats for different papers based on their content, such as MLA and APA, there are even different file types that best suit particular digitization efforts. For example, there are multiple file formats for images, each with their own set of advantages and disadvantages:
- Graphics Interchange Format (GIF) – lower quality, faster to load, small file size
- Joint Photographic Experts Group (JPEG) – decent quality, decent load time, medium file size
- Tagged Image File Format (TIFF) – high quality, slow to load, large file size
- Page images – the document is scanned or photographed and displayed as an image file with little or no user interface, though most of the time zooming is an option
- Mark-up language enhanced or recreated documents – use of a markup language creates more differentiation between areas of text with the use of bold and italic font and increase the ability of the user to interact with the document
- Optical Character Recognition (OCR) – use of a program that extract words from a scanned page (works better with 19th and 20th Century text with larger font) with a 95-99% accuracy to create a highly searchable text version of the original
While the poor quality digitization of a photograph was described as taking a painting from flowing brush strokes on a blank canvas and turning it into dots of color in the individual boxes on a sheet of graph paper in chapter 3 of Cohen & Rosenzweig’s Digital History, I feel that the above issues still face the digitization of text documents equally, complete with a similar example. In calculus, integration is the process of finding the area under a curve. While covering the curve in rectangles of varying height the recreate the general shape of the curve (with more rectangles meaning more accuracy) may give a decent estimate of the area, integration using proper mathematical methods would still yield the best results.
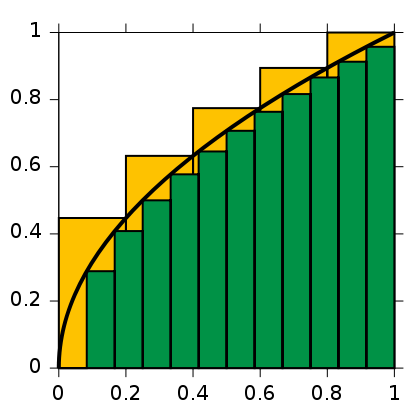
Note how neither set of rectanges accurately represent the area under the curve. [Click image to visit source.
This is similar to how the above forms of digitization still lack valuable pieces of information. Page images would be the small rectangles (such as the green set above), following the document closely but still lacking some of its qualities and making it more crowded and hard to read. Just as the green rectangles would lead to an underestimate of the area under the curve, page images lack the additional qualities that would help weigh out some of the disadvangaes leading to an underrepresentation of what the document has to offer. Mark-up languages would be slightly larger rectangles (perhaps some size between the green and yellow sets displayed above), which overstep the boundary of the curve, much how mark-up languages don’t entirely accurately convey the original document yet add advantages such as bold text or the ability to search the document with the use of keywords.
Finally, large rectangles (such as the yellow set above) would most closely represent OCR digitization, where the document is digitally enriched but faces problems with accuracy. OCR is faster and easier than the alternative (just as drawing less rectangles is faster and easier) and would only roughly follow the original text, though it would mean that the resulting document is searchable. However, the end result for all three methods is the same: an inaccurate representation of the original document. Just as only integration will yield the most accurate answer, only the original physical document will give you all of the flowing, smooth nuances associated with a direct physical contact and analysis.
Conclusion
Even though there are a variety of options to suit different price points and purposes when it comes to digitization of the analog world, none of them quite preserve everything the original piece has to offer. Like those who cringe at the idea of a physical book’s binding being ripped apart in order to undergo the process of digitization, I too cringe at what we are sacrificing just to make use of the new, highly unstable (at least in my opinion) technology we have at our disposal. The greatest crime that present humanity can commit is robbing the future of our records, our knowledge, and our history in the making. Our file formats will cease to be readable and our analog artifacts seem to be devalued by the glossy screens of today’s technological toys, leaving the future with a mysterious of a dark age of instant gratification and a disregard for longevity. While digitization is certainly a valuable way of spread knowledge and creating a “back-up plan,” we are treading a very fine line between having all or having nothing as a digital society.